autograd
basics
Gradients can only be calculated for float tensor.
import torch
import numpy as np
# default Tensor will not requires grad
x = torch.randn(2, 2)
print(x.requires_grad) # False
# check if requires grad
print(x.requires_grad)
print(x) # if x requires_grad, it will print at the end.
# ways to enable gradient
x = torch.randn(2, 2, requires_grad=True) # at creation
x.requires_grad_(True) # in-place function
x.requires_grad = True # directly change attribute
# grad
print(x.grad) # None, the grad value, only meaningful after backward() is called.
print(x.grad_fn) # None, the grad function.
print(x.is_leaf) # True. see below.
leaf
A node is leaf if:
- Initialized explicitly.
- Created by operations on tensors that all do not requires_grad.
- Created by
.detach().
Gradients are only populated to tensors with both required_grad and is_leaf are True.
backward
backward will calculate the target tensor's gradients w.r.t all is_leaf and requires_grad tensors.
# z must be a scalar.
z.backward() # == z.backward(torch.tensor(1.0))
# if z is vector, pass in weights the same shape as z.
z.backward(torch.Tensor([1.0 ,1.0 ,1.0]))
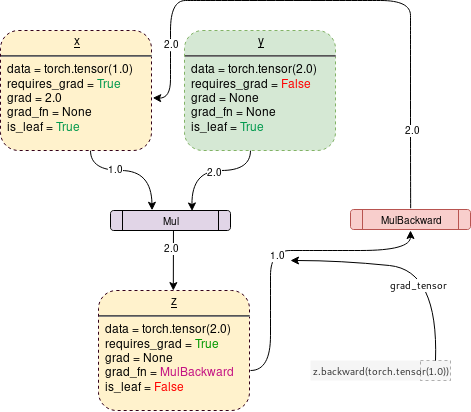
dynamic computation graph
A DAG to track gradient flow.
Example:
import torch
x = torch.tensor(1.0, requires_grad = True)
y = torch.tensor(2.0)
z = x * y
z.backward()
# dz/dx = 2
print(x.grad.data)